optimisation d'un code chatgpt
Et si on regardait différemment le code qu’on produit ?
Depuis 9 mois, j’ai rejoint Davidson pour un poste de « développeur right tech ». Mon objectif était de réconcilier mon activité pro (développeur) avec mes convictions personnelles (et oui je suis écolo ! et mes dernières missions dans le secteur de l’automobile généraient une certaine dissonance cognitive).
Davidson était claire sur les intentions, mais la tâche de créer une feuille de route bien tracée me revenait. Assez rapidement nous validions l’idée de créer un outil de mesure d’impact énergétique multi-critères : je m’y engage avec quelques craintes quant à la dépense (d’énergie justement) occasionnée par l’outil vs les gains potentiels …
Mais ce n’est pas le sujet du jour (un article prochain évoquera les résultats obtenus) car ce dont j’aimerais vous parler ici, c’est de comment cette nouvelle activité m’a fait évoluer sur la question de la relecture de code et notamment sur l’impact de notre façon de coder …
Un matin, confronté à cet extrait de code …

… la première chose qui me vint à l’esprit fut : « Mais pourquoi diable initialiser des variables si c’est pour quitter la fonction juste après, sans les avoir utilisées ?!».
Je réalisai alors qu’en quelques mois, à force de me plonger dans les manifestes d’éco-coding, des articles variés (pas uniquement focalisés sur le code d’ailleurs) et de me m’interroger j’avais fini par déclencher un mécanisme automatique de traque de l’inutile.
Quelques jours plus tard, c’est un peu le « buzz » autour de ChatGPT dans les salons de discussion Discord de Davidson : on commence à voir quelques expérimentations.
Vient l’excellente idée de Rémy qui teste le « bot » en lui soumettant un problème issu de la base de données d’Euler et en le modifiant pour demander la production d’un programme en langage Rust.
Et, je dois bien le dire, il est difficile de ne pas être épaté par la réponse donnée :

Suivant l’orientation des questions (ajout d’optimized, efficient, etc.) la réponse varie quelque peu mais la logique de boucles imbriquées est toujours présente.
Bref, après un gentil copié/collé et quelques ajustements de syntaxe, ça compile, ça s’exécute et au obtient le bon résultat. Le tout en moins de temps qu’il m’en faut pour comprendre l’énoncé du problème .. Waouh !
Un premier regard critique
Sur mon poste de travail, l’exécution est quasi immédiate. Le développeur que j’étais en 2021 aurait pu s’arrêter là … Mais « la traque de l’inutile » rejoint bien souvent les problématiques d’optimisation et active donc les réflexes liés aux boucles. Surtout qu’ici nous en avons 2 imbriquées !
Finalement, il y a peut-être quelque chose à gratter, et je pressens que ça ne doit pas être si anodin…
Histoire d’être un peu factuel, je modifie le code de façon à comptabiliser le nombre d’itérations nécessaires à la production du résultat :
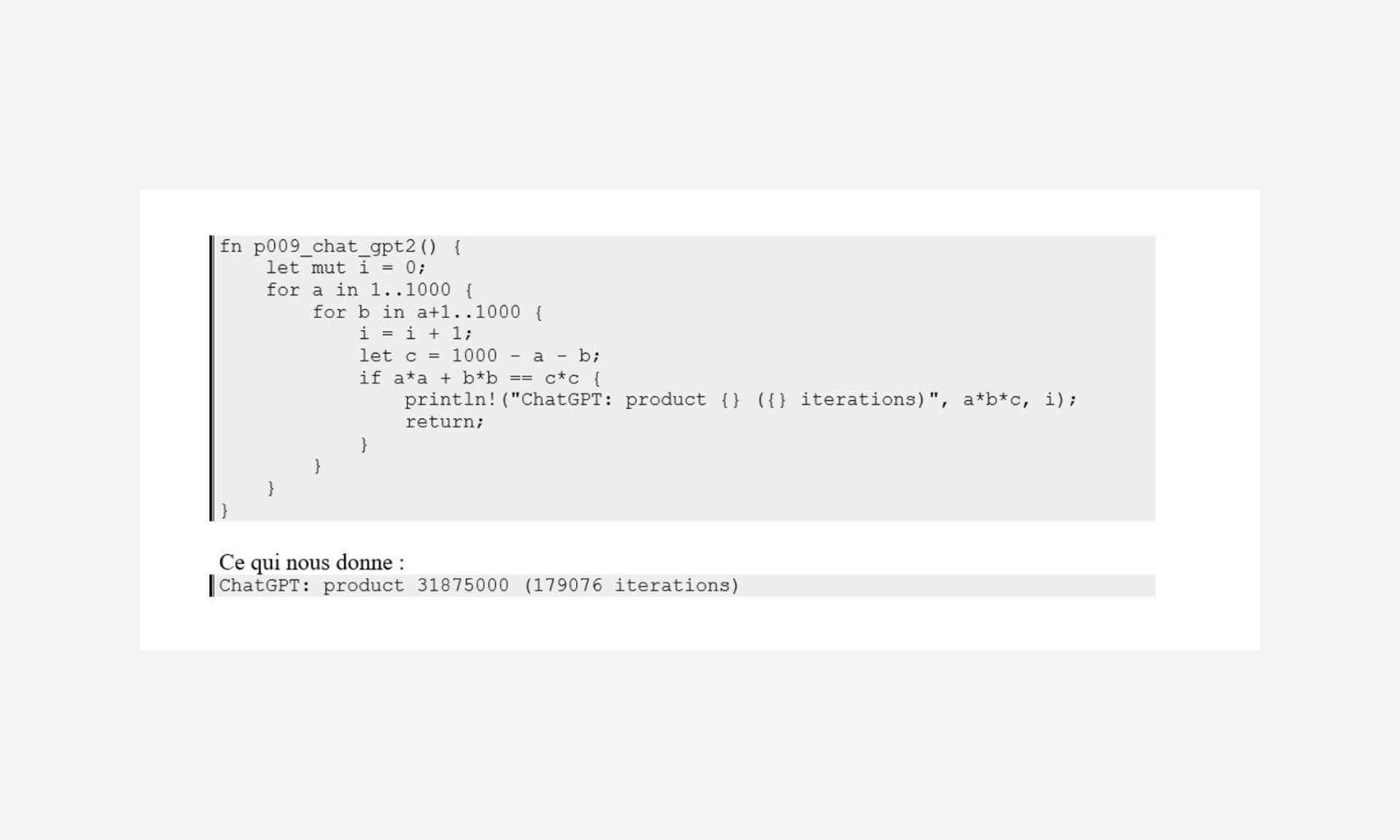
Bien, bien, voici une bonne base de départ…
En regardant un peu plus attentivement ce programme, on voit assez facilement 2 écueils classiques des boucles :
- on teste sur une liste de valeurs non pertinentes
- on dépasse des limites qui rendent le sujet « débile » avec des valeurs de c négatives
Bref, nous sommes en approche « force brute », un peu optimisée quand même (la deuxième boucle part bien à a+1), mais où finalement l’acceptation ne se fait que grâce à la rapidité de la machine et à la recherche sur un ordre de grandeur faible :1000.
Un petit coup de « debug » juste pour montrer l’ineptie de certains tests :

Donc on pourrait déjà améliorer l’affaire en jouant sur les bornes de recherche, mais je vais laisser ça pour un deuxième temps car il sera toujours temps de le faire si on arrive à réduire les recherches sur des valeurs pertinentes. J’entends par là des « pythagorean triplet » valides.
Réduire l’espace de recherche
L’une des plus grosses optimisations possibles sur les boucles est bien le fait de réduire le nombre de cas à tester. Il est évident que si on teste un potentiel de 10000 cas on sera moins pertinent que si on teste un potentiel de 100 cas.
Dans un cas un peu plus « standard » de programmation : si une base de données permet d’avoir un critère discriminant permettant de restreindre l’ensemble de données la création d’un index et le filtrage sur ce critère permet des gains non négligeables.
Mais un filtrage est lui-même une opération qui a un coût et, dans notre cas, il est intéressant de s’interroger sur la nature même de ce que l’on manipule, et s’il n’y a pas de propriétés particulières.
Une petite recherche internet plus tard et je tombe sur « Euclid’s formula » :

Pas mal car cela va restreindre le champ de recherche en faisant des boucles sur les paramètres m et n sur des « triplet » valides.
Voici donc une première tentative d’optimisation :

S’échapper des boucles
Dans la première optimisation, les bornes des boucles sont définies avec une cote grosse maille, et comme noté sur la version issue de ChatGPT, on doit pouvoir réduire le nombre de cas en les définissant correctement.
Mais dans ce qui est plus directement accessible, il est facile de se dire que si la somme de a, b et c augmente à chaque itération : une fois dépasser 1000, il est possible de s’échapper de la boucle faisant varier m pour repartir avec une nouvelle valeur de n.
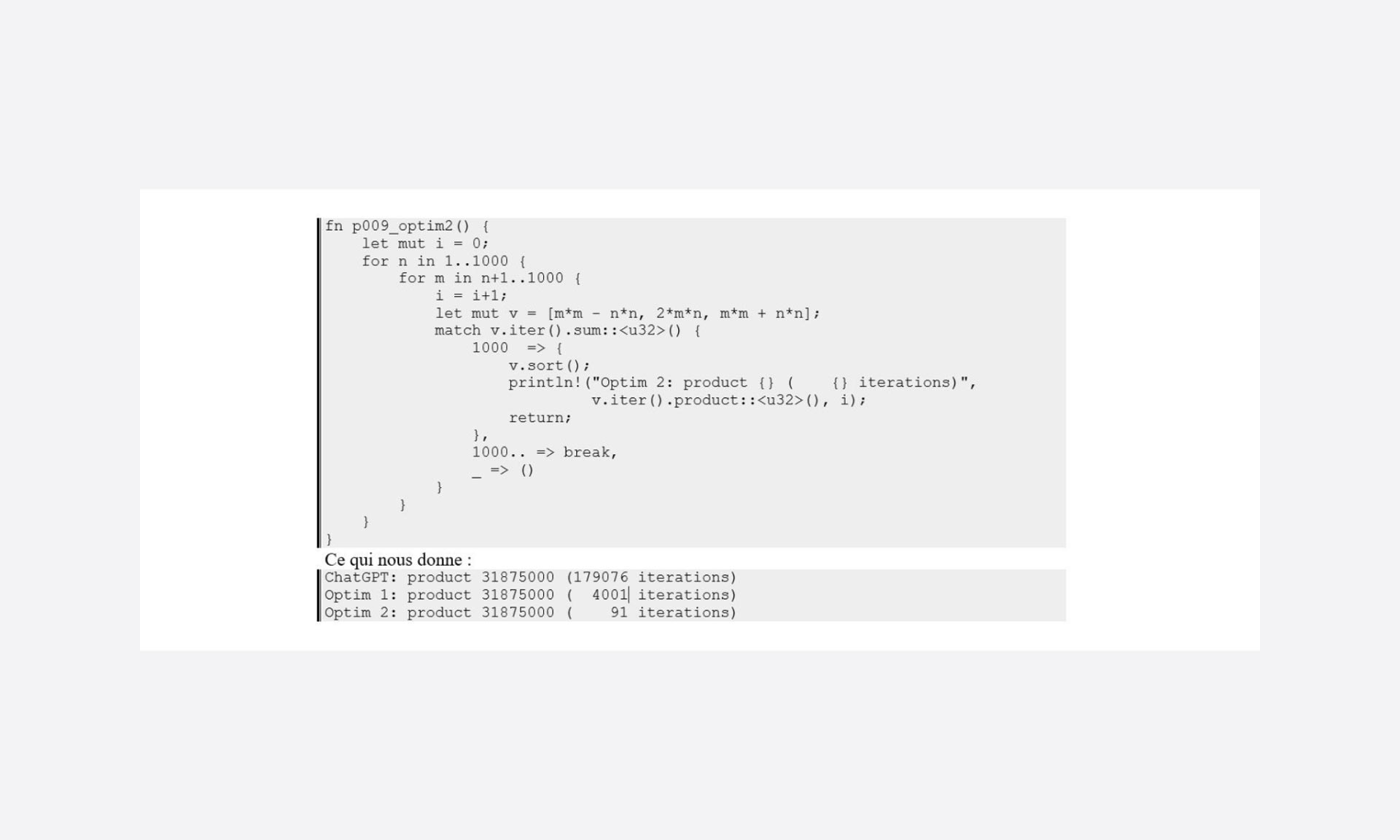
Encore un belle optimisation qui ne marche toutefois que si l’on est confronté à des suites de tests incrémentales.
Mais, juste sur des conditions de sortie de boucle, le gain est plus que significatif.
Efficacité de la méthode recherche
Malgré la réduction drastique du nombre de cas à tester pour parvenir à la solution, notre programme continue à tester tous les cas possibles en mode incrémental.
Mais justement, le fait de travailler sur quelque chose d’ordonné nous permet d’envisager d’utiliser différents algorithmes de recherche. Vu la plage de données (1000) on peut tenter une approche dichotomique.
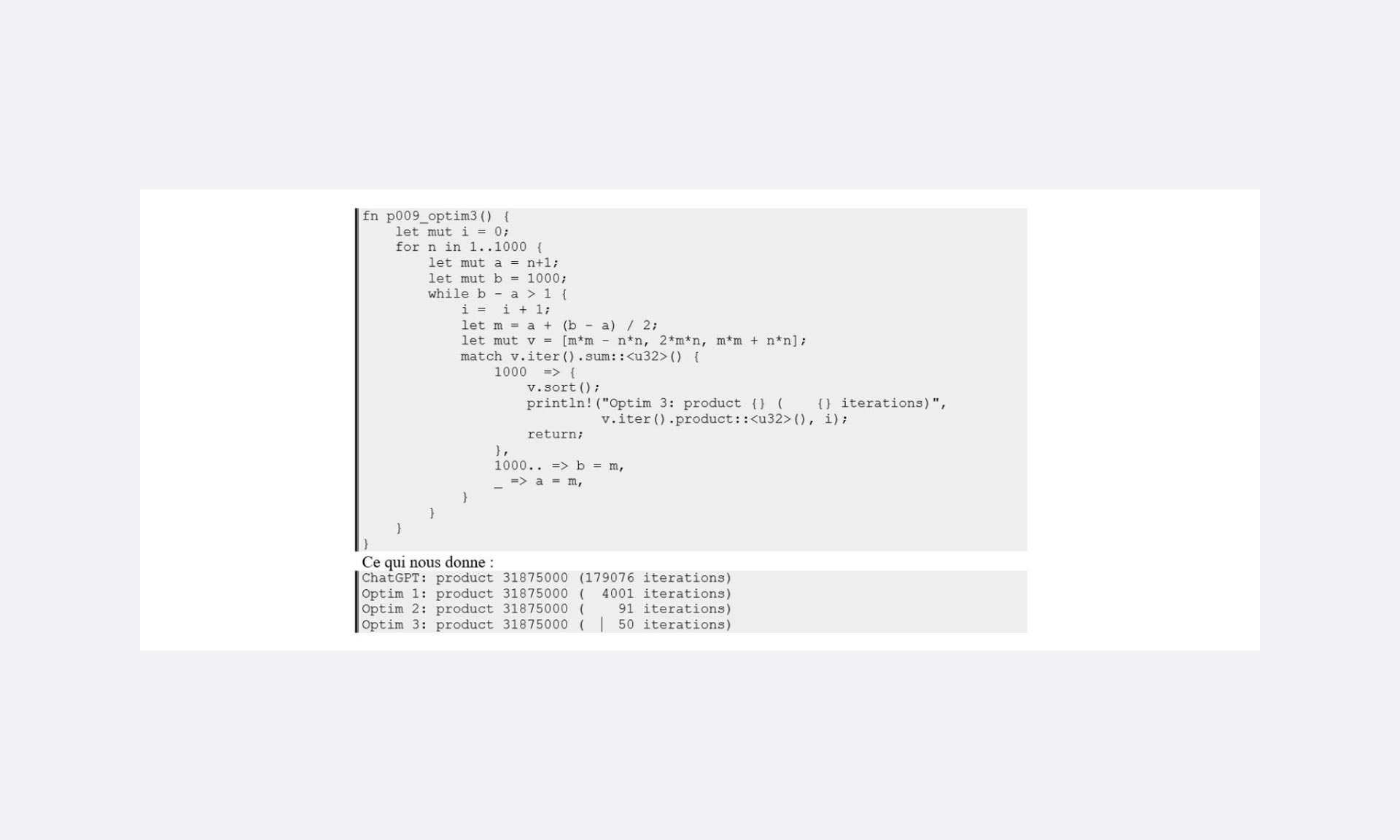
Un petit gain, mais quand même 45 % de l’optimisation 2. (On peut noter que l’objet de l’optimisation 2 est annulé par l’utilisation de ce type de recherche, ça n’enlève en rien son intérêt c’est juste non applicable dans cette méthode de recherche)
Pour les algorithmes de recherche, leur complexité, leur intérêt, internet regorge d’articles sur le sujet et de nombreuses librairies les proposent en standard.
Ce qu’il faut en retenir ici, c’est que dans le cas de listes, de boucles ordonnées, suivant la plage de données, l’utilisation d’un tri rapide peut rapidement faire économiser beaucoup d’itérations.
Affinage des bornes
Toujours dans l’optique de réduire le nombre de cas testés, l’amplitude de variation de n et m fixée arbitrairement à 1000 doit pouvoir être bien mieux ajustée.
Ici, on est sur un problème fixé sur une somme du triplet à 1000, et comme on travaille sur des itérations croissantes, on peut pré-calculer les bornes.
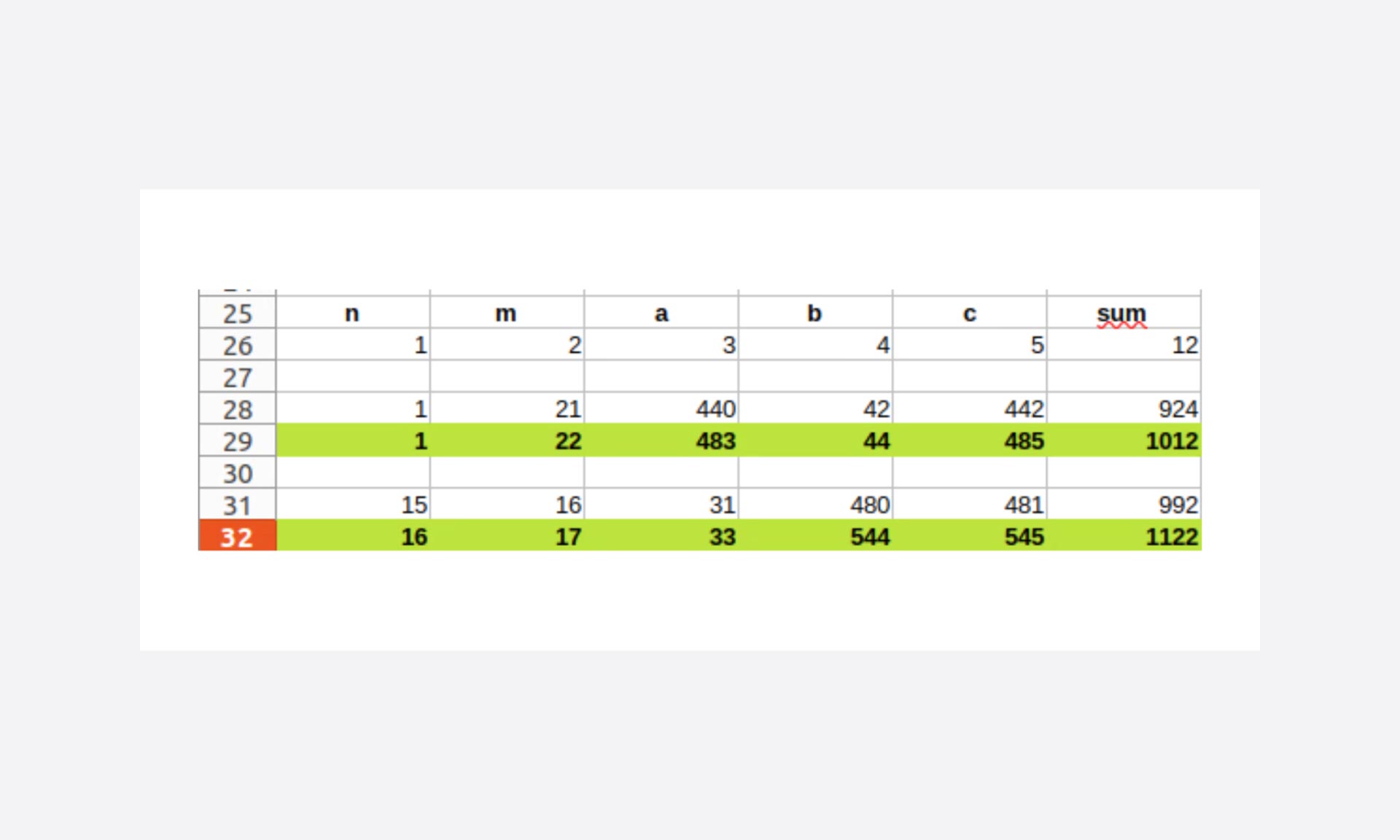
Donc on obtient rapidement que :
- dans le cas où n = 1, m doit au maximum être à 22
- la limite pour trouver la solution est avec n = 16 et m = 17
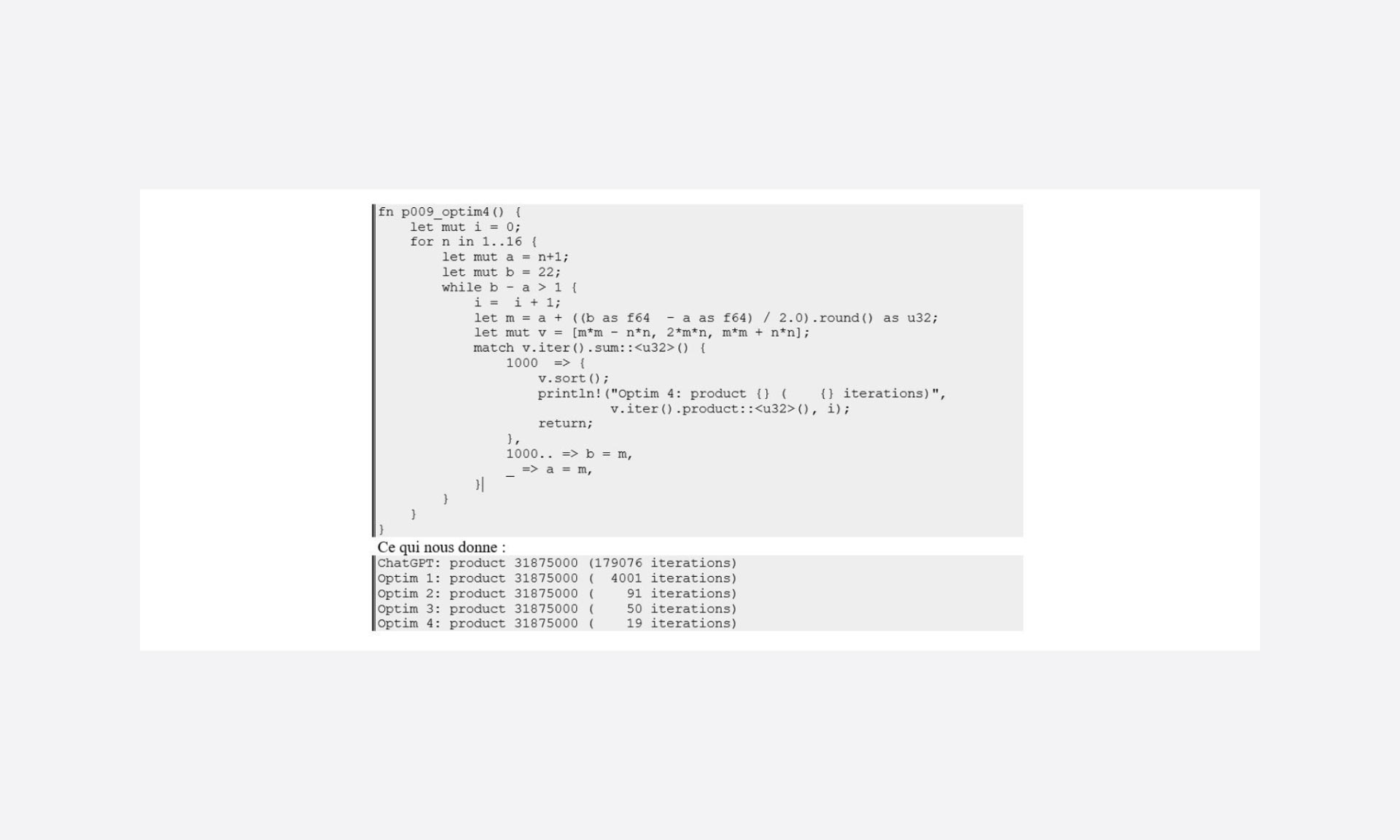
Le bon « bornage » des boucles permet également d’éviter un bon nombre d’itérations.
La traque de l’inutile
J’ai essayé de présenter ici le déroulé d’une matinée « d’entraînement » : le parcours n’est pas optimal, et je ne prétends pas non plus que le résultat le soit (je ne suis sans doute pas assez calé en mathématiques pour cela).
L’exemple choisi ici n’a finalement que peu d’intérêt dans la mesure où l’on cherche toujours le même résultat et que la puissance de nos machines rend cette optimisation non perceptible en termes d’expérience utilisateur (temps d’attente pour avoir la réponse).
Il n’en serait pas tout à fait de même si l’on souhaitait l’utiliser pour d’autres recherches : somme du triplet en variable (actuellement de 1000).
D’un point de vue développeur, on peut tout même retenir l’importance :
- de la minimisation du jeu de données
- de l’ajustement des bornes de recherche
- de l’utilisation de méthodes de tri/recherche
- de s’échapper des boucles en cas de boucles imbriquées
Il s’agit là de points d’attention à avoir :
- personnellement, lors de la création de code
- collectivement, lors des code review
Ce petit exercice ne présente cependant qu’une facette de la pensée « Right Tech » appliquée au développement logiciel et finalement, j’ai juste réalisé un travail d’optimisation (et ceci, simplement au niveau algorithme).
La partie intéressante réside dans le fait de rechercher une optimisation sans qu’elle soit directement liée à un problème de performance vécu, ressenti.
Et c’est bien là le changement de paradigme contemporain visant à anticiper la réduction des ressources en essayant de les exploiter au mieux, pour plus de partage, plus de richesses.
L’informatique et le code sont exagérément trompeurs sur ce sujet car nous sommes réellement dans un contexte où, tant que l’expérience utilisateur ne semble pas pénalisée, nous ne recherchons pas la juste utilisation de la puissance mise à disposition. Et finalement nous ne sommes vraiment pas loin des mécanismes retardant la prise de conscience écologique.
Le corollaire peut être honteusement résumé en 2 points :
- il faut re-éduquer notre façon de voir le code pour identifier le superflu (et l’on peut s’aider d’outils comme Ecocode)
- nos « managers » et nos « clients » doivent nous donner également le temps d’effectuer ce travail (par exemple sous forme d’indicateurs prenant place à côté des classiques qualité, coûts, délais)
La partie software est certainement celle qui est le moins impactante en terme de bilan carbone, mais avoir cette attention de la traque de l’inutile quand il s’agit de concevoir et de réaliser du code a un impact direct sur l’obsolescence du matériel dans la mesure où nous l’utilisons plus efficacement.
Pour les curieux, j’ai réalisé un test en cherchant le triplet ayant une somme de 50000…
| Recherche somme du triplet 5000 | |||
| Itérations | Secondes | Joules | |
| ChatGPT | 449953751 | 9,37 | 113,059315 |
| Optim 4 | 512 | 0,11 | 0,419751 |
Les secondes via l’outil unix time, les Joules via l’outils vjoules issue de powerapi
Je vous laisse l’exercice de l’ordre de grandeur, en gardant en tête qu’en informatique le temps, c’est de l’énergie consommée.
Et si l’on entraînait ChatGPT pour qu’il prenne en compte les problématiques d’écoconception lors de la production de code ?
Vincent CAGNARD – developpeur Right Tech chez Davidson