Qu’est ce que le DevOps ?
L’approche DevOps se caractérise par le rapprochement du développement logiciel (Dev) et de l’administration des infrastructures informatiques (Ops). Sa mise en œuvre nécessite la mise en place d’un Workflow de monitoring stratégique. Ce monitoring permet d’assurer la haute disponibilité et les performances des services cloud dans des environnements en évolution rapide.
Dans cette approche, la supervision est un élément essentiel à la fois pour les équipes Dev et Ops. Elle permet de tracer avec efficacité les activités d’un système d’information. Sans supervision, il ne serait pas possible de réagir automatiquement et rapidement pour corriger toute anomalie au niveau de l’application. Dans cet article nous revenons sur la stratégie et les outils que nous avons mis en place pour répondre à ces besoins.
Il était une fois chez Davidson…
Chez Dav’ nous hébergeons, comme beaucoup, les applications développées par Twister (notre DSI) sur deux types d’environnements :
- Cloud (Openshift)
- “On Premise”
Les applications hébergées dans les deux types environnements exécutent des Crons: des CronJobs Openshift au niveau des applications hébergées sur le cloud Openshift et des Crons système qui s’exécutent au niveau de l’infrastructure OnPermise.
Ce sont ces Crons qui permettent de planifier l’exécution d’une tâche ainsi que sa périodicité.
Techniquement, les Crons varient en fonction du type d’hébergement :
- OpenShift utilise des CronJob OpenShift. La tâche CronJob crée un template en langage YML qui produit un job / pod Kubernetes.
- Sur les VM de l’infrastructure On Premise, des commandes Linux lancent des Crons systèmes. Chaque Cron est composée de trois éléments : le script à exécuter, la commande qui exécute le script et l’action ou le journal du script.
Le monitoring varie également en fonction du type d’environnement :
- Sur OpenShift, les CronJobs sont surveillés avec la solution de monitoring Prometheus configurée au niveau d’Openshift.
- Sur les VMs de l’environnement On Premise, certaines applications Web sont déjà supervisées grâce à la solution de monitoring Grafana.
Cependant, il n’existe pas de moyen unifié de surveiller simultanément l’état de ces Crons. En d’autres termes, si l’exécution d’un CronJob ou d’un Cron système échoue, l’équipe Ops ne pourra pas disposer rapidement de cette information centralisée pour les deux types des Crons.
Pour améliorer la supervision des applications, notre projet présente deux objectifs :
- Assurer le monitoring et la visualisation de l’état de santé de ces 2 types de Cron de façon centralisée.
- Visualiser dans un dashboard unique l’état dernier de chaque Cron.
Choix des outils
Openshift
Openshift est une plate-forme cloud hybride et open source de RedHat. Elle est conçue pour le développement, le déploiement et la gestion des applications. Elle fournit aux développeurs un environnement intégré pour créer et déployer des conteneurs Docker, puis les gérer avec la plate-forme open source d’orchestration Kubernetes.
Avec cette combinaison, Openshift permet à toute application de s’exécuter partout où les conteneurs Docker sont pris en charge.
Une fois que les développeurs envoient leurs codes vers Openshift, ce dernier se charge d’orchestrer comment et quand les applications s’exécutent. Il permet également aux équipes de développement de corriger, d’affiner et de faire évoluer leurs applications.
Openshift fournit également un catalogue en ligne. Certaines catégories populaires incluent la gestion des conteneurs, le développement d’applications mobiles, les systèmes d’exploitation, les langages de programmation, la journalisation, la surveillance ou encore la gestion de bases de données.
Forte d’une communauté de contributeurs très large, Openshift présente pour nous de nombreux intérêts :
- l’accélération du développement des applications ;
- plusieurs moyens de gérer et d’automatiser les conteneurs ;
- l’auto scalabilité en fonction des ressources, du trafic et des conditions à définir ;
- le doublement du nombre des Pods pour améliorer les performances des applications ;
- la possibilité de faire un Rollback ;
- les avantages de la conteneurisation par rapport au VMs (portabilité, gestion réduite, conteneurs plus légers et plus performants, etc.).
Supervision d’OpenShift
Quant aux solutions de supervision, les entreprises ont le choix entre plusieurs outils de DevOps utiles pour faciliter le processus, parmi lesquelles : SolarWinds, Nagios, Zabbix, Prometheus, Graphite, Centreon, etc.
Les besoins à prendre en compte pour sélectionner une solution de supervision sont les suivants :
- l’identification des problèmes et l’envoi des alertes à l’administrateur ;
- l’enregistrement et le traçage des informations et de l’historique en temps réel ;
- la création de Dashboard personnalisés.
Pour répondre à ces besoins, nous avons sélectionné les Stack Monitoring Prometheus & Grafana. Les avantages sont les suivants :
- Prometheus et Grafana peuvent être utilisés comme des services complémentaires.
- Combinés, ils fournissent une base de données de séries chronologiques robuste, avec une excellente visualisation des données.
- Ces deux outils sont largement utilisés pour superviser les applications dans des environnements à base de conteneurs.
- Preuve de la maturité de cette solution, Prometheus et Grafana constituent la stack de monitoring par défaut d’OpenShift.
Prometheus
Prometheus est un outil créé par la plateforme SoundCloud. Il s’agit d’un système de surveillance et d’alerte open source, considéré comme une base de données de séries chronologiques en temps réel avec un langage de requête PromQL. Prometheus est largement utilisé dans les workflows modernes de DevOps, notamment pour les infrastructures à base de conteneurs et de microservices.
L’image ci-dessous présente l’architecture de Prometheus :
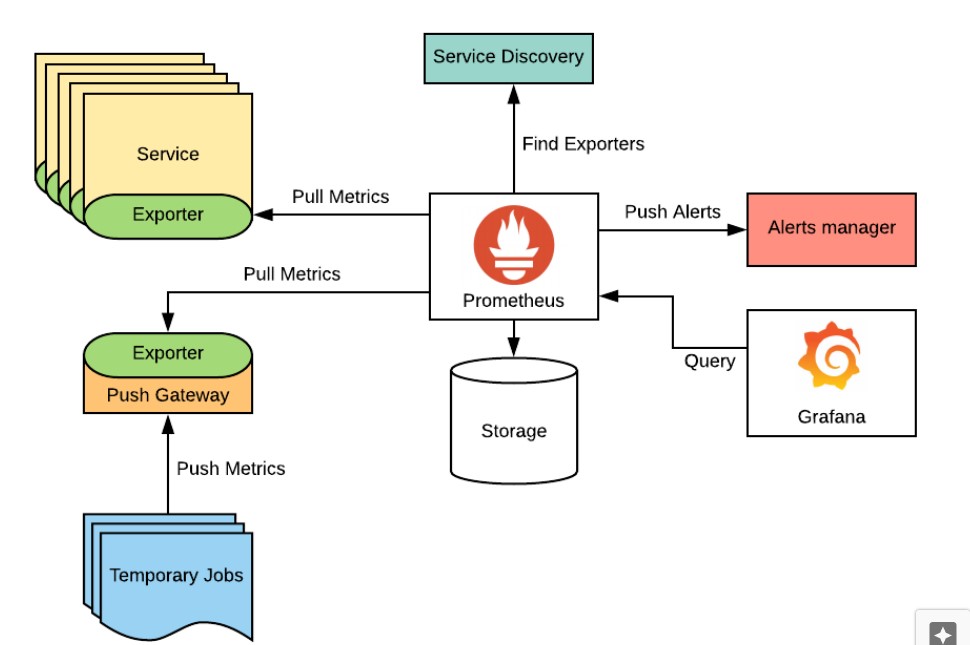
- Le serveur Prometheus : il collecte les métriques sous forme de données de séries chronologiques à partir des nœuds et les stocke dans sa base de données.
- Les exporters : ces composants permettent d’exposer les métriques de Prometheus et les exposent via un Endpoint, selon un format spécifique (en PromQL) .Les librairies clientes : Prometheus stocke les données dans un format de série chronologique et n’accepte que les données dans ce format. Dans certains cas d’utilisation, où il ne s’agit pas d’exporters bien définis pour exposer les métriques, il faut manuellement passer par un processus d’« instrumentation », qui permet de définir des métriques personnalisées que Prometheus pourra collecter.
- Le PushGateway : parfois il y a des jobs dont la durée de vie est plus courte que l’intervalle de scraping (ou période de collecte des métriques) de Prometheus. Le Push Prometheus intervient pour permettre à ce type de jobs d’exposer leurs métriques à Prometheus.
- L’alerte Manager : cette entité gère les alertes envoyées par les applications clientes. Elle s’occupe de l’acheminement des alertes vers des canaux de communications tels que le courriel, Slack, Discord, etc.
- Web IU : ce composant est conçu pour visualiser et exporter des données depuis Prometheus en exécutant des requêtes PromQL. Il exploite les règles d’alerte manager, la configuration, les machines cibles, etc.
- Service Discovery : pour minimiser les configurations, Prometheus effectue une découverte automatique des services qui s’exécutent, par exemple sur des environnements Kubernetes.
Grafana
Grafana est une solution open source qui analyse les données, extrait les métriques provenant de plusieurs applications et surveille les applications à l’aide d’un Dashboard personnalisable.
Grafana peut se connecter à plusieurs Data Source, appelées bases de données telles que Graphite, Prometheus, InfluxDB, ElasticSearch, MySQL, PostgreSQL, etc. Enfin, le Dashboard Grafana permet de prendre en charge plusieurs Rows et Panels, l’utilisateur peut également visualiser les résultats de différentes sources de données simultanément.
L’image ci-dessous présente l’architecture combinée de Prometheus et Grafana :
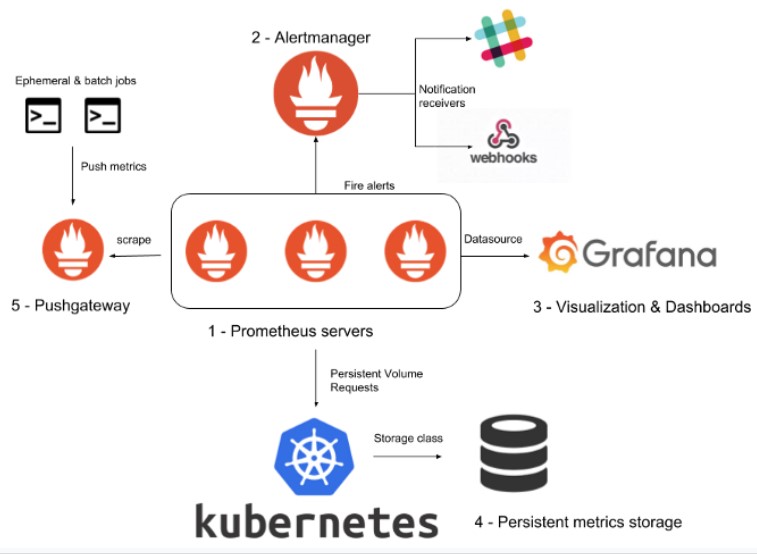
Pourquoi associer Prometheus & Grafana ?
Premièrement, ces deux outils sont open source et largement adoptés. Ils peuvent être facilement déployés pour les installations de base et sont très efficaces. Ils disposent également d’un support pour la version “entreprise”.
Deuxièmement, Prometheus & Grafana regroupent une large communauté de contributeurs, ce qui aide à anticiper un grand nombre de cas d’utilisation et permet de trouver des solutions adaptées à diverses problématiques.
Enfin, en plus d’être packagés par défaut avec OpenShift, nous les utilisons déjà sur notre cluster pour superviser d’autres éléments. Par ailleurs Prometheus est déjà configuré pour superviser l’état des CronJobs Openshift.
Architecture applicative
Existant
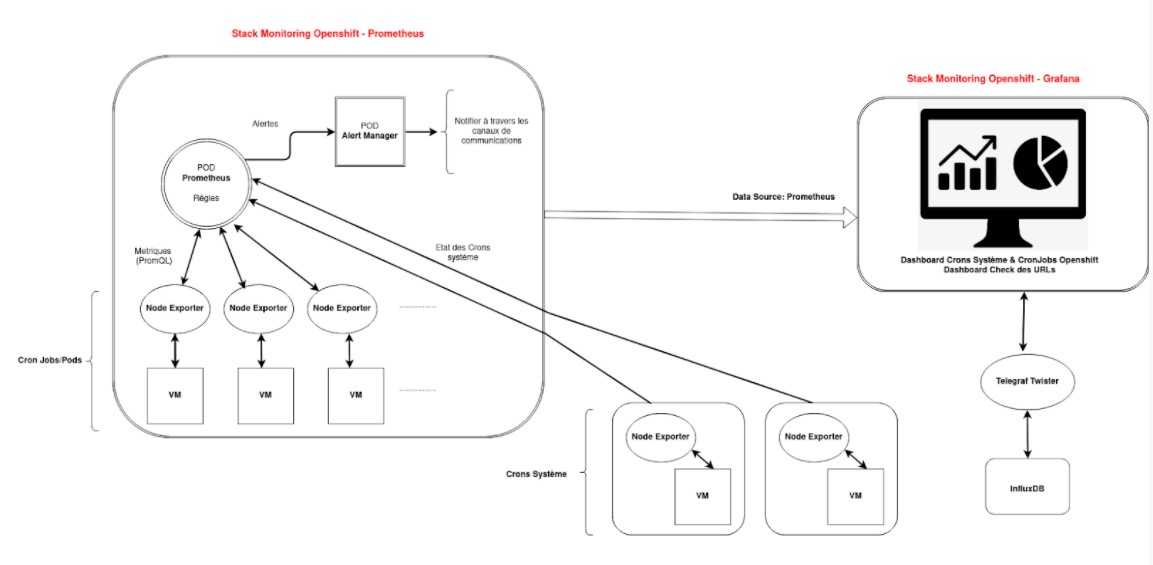
Prometheus et Grafana supervisent les CronJob OpenShift et les applications.
Supervision des CronJobs OpenShift
Le fonctionnement est le suivant :
- des CronJob créent chacun un job puis un pod ;
- dans OpenShift, le Pod Prometheus est connecté à ces autres Pods ;
- ces Pods envoient leurs métriques à Prometheus. Prometheus est ainsi informé de l’état des CronJobs.
Pour mettre en œuvre ce setup, nous avons procédé de la façon suivante :
- configurer un Node Exporter pour chaque machine virtuelle dans le cluster Openshift ;
- configurer des règles, en se basant sur des métriques ;
- configurer les alertes au niveau de Prometheus et de l’Alert Manager.
Supervision des applications
Le fonctionnement est le suivant:
- La Stack Monitoring Grafana est configurée avec la Data source Telegraf Twister.
- Telegraf envoie des informations liées aux réponses HTTP des différentes applications.
- Ces informations sont analysées à l’aide de requêtes InfluxQ.
- Un dashboard affiche, pour chaque application, les infos suivantes :
- La dernière réponse HTTP pour chaque application.
- La réponse en Milliseconde de chaque application.
Cible
À cet existant nous allons ajouter deux éléments :
- La supervision de l’état de santé des Crons système qui tournent sur des VMs en dehors du cluster Openshift.
- La supervision de la durée de la non-réponse des différentes applications et la génération d’alertes.
Supervision des Cron Système
Pour superviser l’état de santé de ces Cron systèmes qui tournent sur des VMs en dehors du cluster Openshift, nous procédons de la façon suivante :
- Connecter ces VM au Pod Prometheus.
- Sur les VM, configurer les nodes exporters pour envoyer l’état des Crons système via des métriques à Prometheus.
- Dans Prometheus, en exploitant ces métriques, configurer des règles pour déclencher des alertes.
- Dans un Dashboard Grafana, visualiser l’état dernier de chaque CronJobs Openshift et de chaque Cron système.
Supervision des applications
Pour superviser la durée de la non-réponse des différentes applications et la génération des alertes, nous allons exploiter la dernière réponse HTTP de chaque application :
- un Dashboard Grafana permettra la visualisation de la durée de la non-réponse de chaque application ;
- en cas de la non-réponse d’une des applications, Grafana générera une alerte.
Réalisation & résultats
Supervision des CronJobs Openshift & des Crons Système
Liaison des VM au Pod Prometheus
Nous avons lié le Pod Prometheus aux VMs qui font tourner des Crons système en dehors du cluster Openshift.
Un exemple est présenté ci-dessous avec ‘eos’. Il s’agit d’une application interne développée par l’équipe Twister en PHP pour la gestion de la base de données centrale des salariés de Davidson.
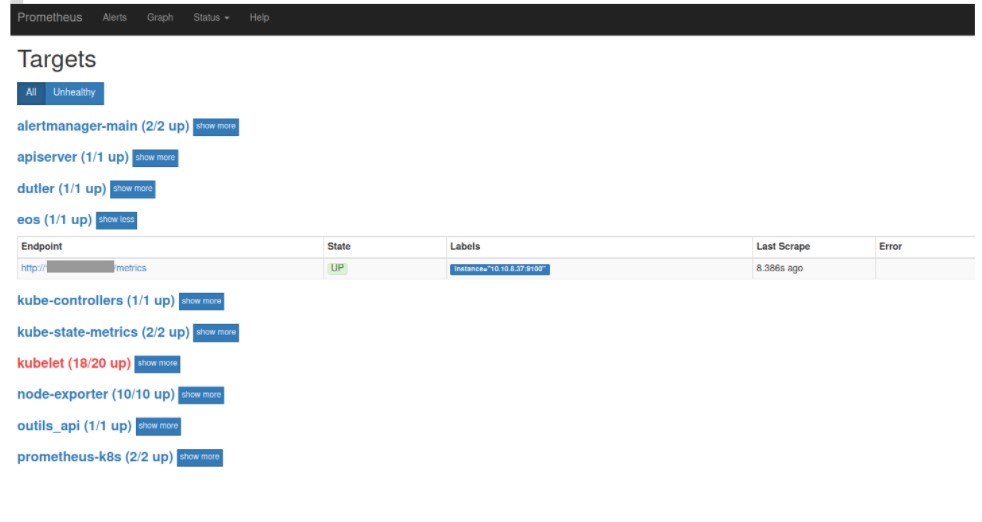
Remontée des métriques
Dans un deuxième temps, chaque VM ajoutée doit être configurée de manière à envoyer ses métriques Cron système.
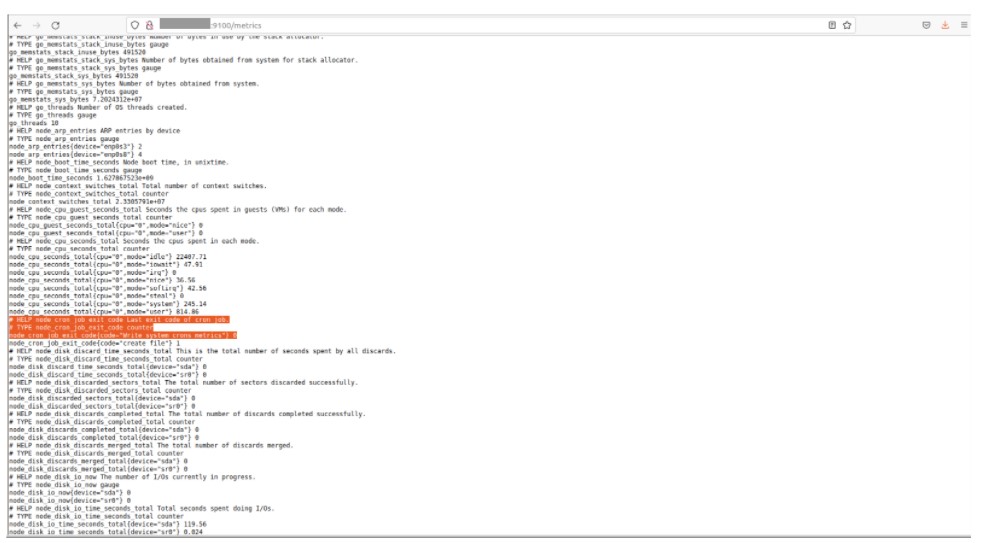
C’est l’étape la plus importante, car Prometheus ne dispose pas par défaut des métriques pour informer de l’état des Crons système. Habituellement, il faut configurer un exporter mais, pour les Crons, aucun exporter n’est disponible.
Nous pallions à cette absence de la façon suivante :
- Configuration d’un Node exporter dans chaque VMs en dehors du cluster Openshift.
- Ajout des machines cibles dans la configuration de base du serveur Prometheus.
- Mise en place d’un script Bash qui va personnaliser et envoyer les métriques décrivant l’état des Crons Système (0 pour succès, 1 pour échec).
- Configuration du ‘Node Textfile Collector’ pour parser toutes les métriques enregistrées.
- Configuration d’une règle qui va servir à l’affichage des alertes au cas où l’exécution d’un Cron échouerait.
L’image ci-dessous affiche une métrique configurée correspondant à l’état d’un Cron système qui renvoie 0.
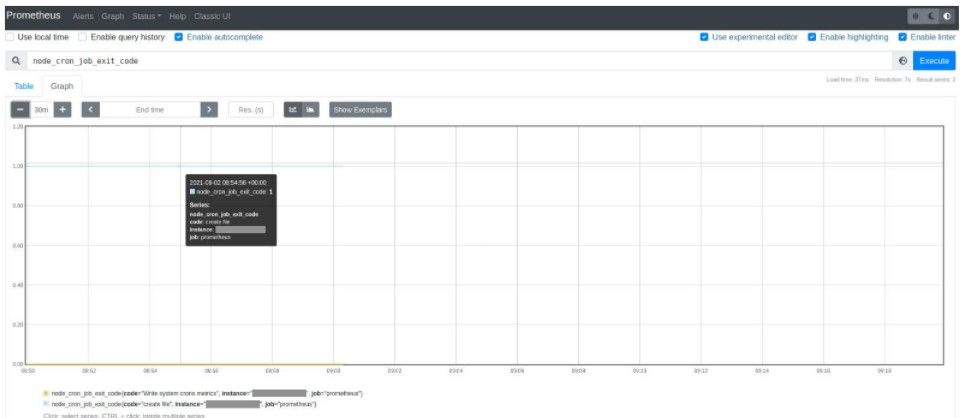
Prometheus fournit la possibilité de visualiser, à l’aide d’une courbe, les informations qui sont renvoyées par la métrique.
Alerting
À la suite de la configuration d’une règle, au cas où le Cron ne s’exécutera pas correctement, une alerte va s’afficher :
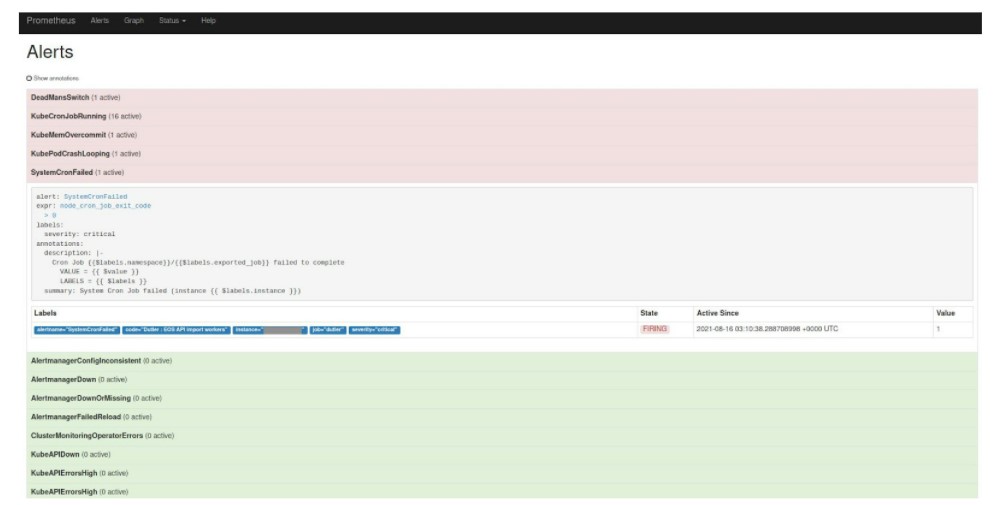
Il y a également les règles / alertes déjà configurées (par rapport à l’existant) pour remonter l’état des CronJobs Openshift.
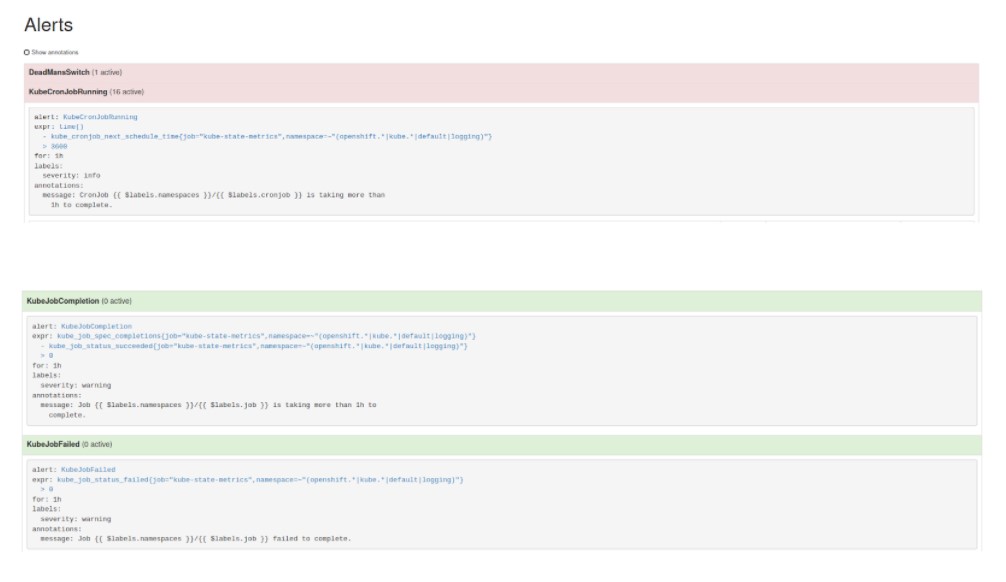
Dashboard
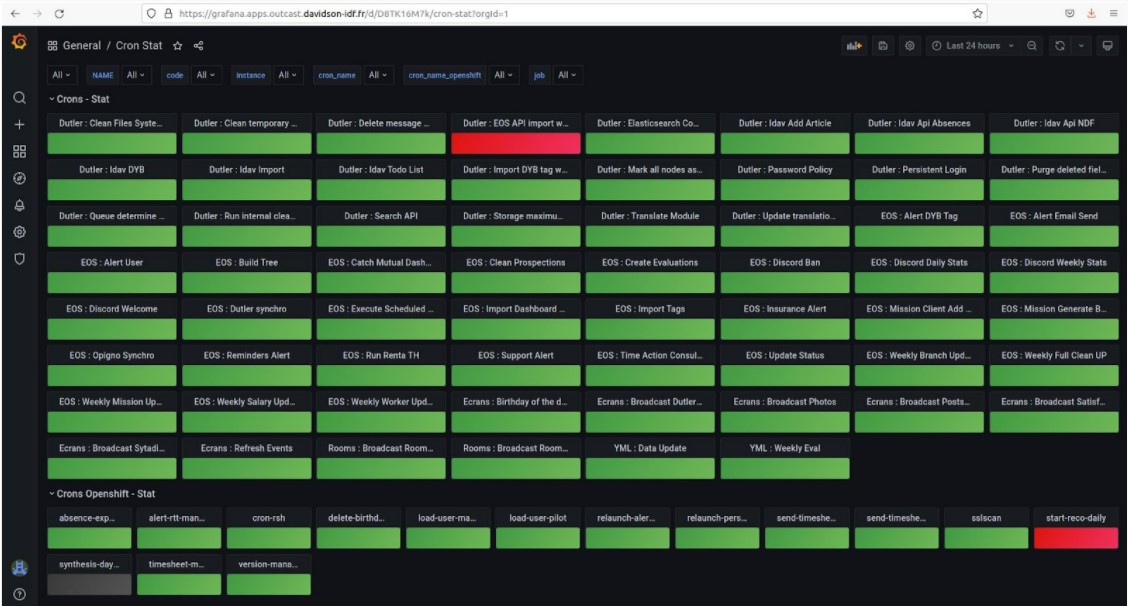
On disposera de plus de la possibilité de visualiser à la fois l’état de tous les Crons système et l’état des CronJobs Openshift au niveau d’un Dashboard Grafana.
Le Dashboard ci-dessous est composé de deux ‘Rows’. Chacun correspond à une catégorie de Cron et chaque Cron est présenté sous la forme d’une Panel.
- Le Row ‘Crons – Stat’ présente tous les Crons système.
- Le Row ‘Crons Openshift – Stat’ présente tous les CronJobs Openshift.
- En vert, les Crons qui se sont correctement exécutés.
- En rouge, les Crons qui ont échoué.
En ce qui concerne la gestion des alertes, la suite du processus en cas d’incident et les actions qui doivent être prises pour assurer le bon traitement, nous avons considéré quelques points importants pour répondre aux besoins de notre projet : un système de monitoring efficace pour l’équipe Ops, qui apporte une réponse rapide lors de l’échec d’un Cron.
Le Dashboard sera affiché dans un écran, face de toute l’équipe Dev & Ops.
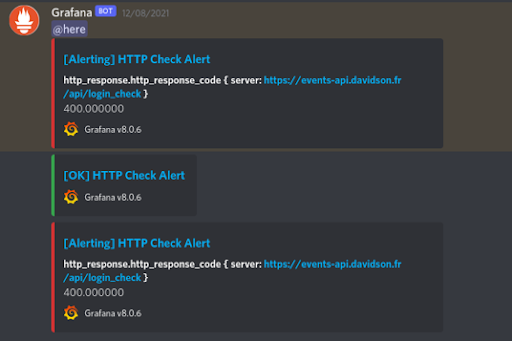
L’alerte manager de Prometheus va envoyer les alertes pour les CronJobs Openshift via les deux canaux de communication : courriel & Discord.
Ci-dessous, un exemple d’une alerte envoyée par l’alerte manager de Prometheus via l’email.
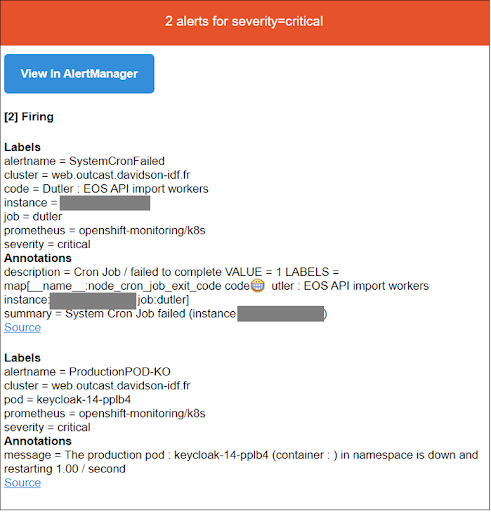
Dans la même mesure, et pour ne pas troubler l’équipe Dev, l’équipe Ops est destinataire des alertes, notamment pour mener la première analyse en fonction de l’anomalie remontée, qu’elle priorise et communique ensuite à l’équipe Dev.
Supervision des Applications
Pour les applications, un Dashboard Grafana ‘HTTP Response Monitoring Twister’ existe déjà pour visualiser :
- l’état de la dernière réponse HTTP de chaque application ;
- le temps de réponse en milliseconde de chaque application sur un intervalle de temps donné.
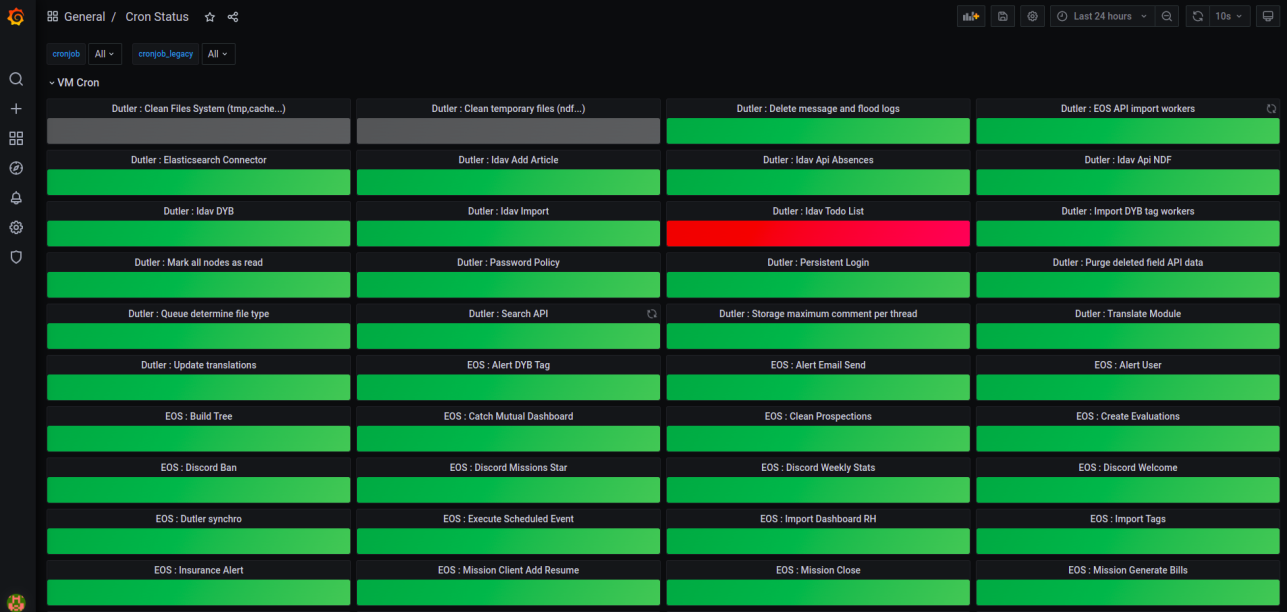
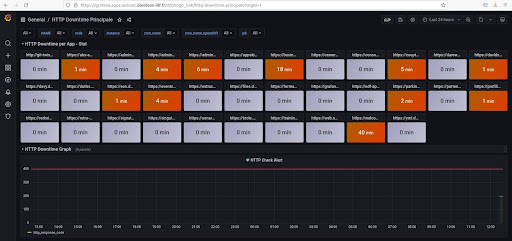
Il faut ensuite créer un autre Dashboard ‘HTTP Downtime’.
- Le premier Row ‘HTTP Downtime per App – Stat’ affiche pour chaque panel, le temps de la non-réponse d’une application, sur un intervalle de temps à sélectionner en haut du Dashboard.
- Le deuxième Row ‘HTTP Downtime Graph’ permet de visualiser pour chaque application les 60 dernières réponses HTTP.
Dans la suite de ce process et de la gestion des alertes, ces mesures peuvent s’appliquer à l’alerte manager de Grafana, qui a été configuré pour envoyer les alertes sur le salon Discord dédié, au cas où la réponse HTTP est égale ou supérieure à 400.
En conclusion
Dans cet article, nous avons abordé notre approche du monitoring DevOps à travers laquelle nous avons pu voir les différents aspects théoriques et pratiques liés aux Crons système, CronJobs, Openshift, Prometheus & Grafana et la façon dont tous ces éléments interagissent.
Résultat
Nous avons pu mettre en place un système unifié pour visualiser des Crons qui s’exécutent à l’intérieur et en dehors du Cluster Openshift, pour permettre à l’équipe DevOps de prendre rapidement les mesures appropriées en cas d’alertes.