Le MLOps dans le Cloud qu’est-ce que c’est ?
Le travail au quotidien d’un Data Scientist peut consister notamment à entrainer des modèles prédictifs de Machine Learning ou de Deep Learning. Il arrive que cette tâche soit conduite de manière un peu … artisanale : tests réalisés sur un poste local, résultats non partagés, code non optimisé, etc. En outre, un Data Scientist n’est pas nécessairement formé pour déployer des modèles en production.
C’est pourquoi les trois acteurs principaux du Cloud (Amazon, Google et Microsoft) proposent aujourd’hui des outils pour faciliter le travail du Data Scientist. Ils répondent aux noms de :
- SageMaker (Amazon)
- Vertex AI (Google)
- Azure Machine Learning Studio (Microsoft)
L’objectif de cet article est de présenter les fonctionnalités principales qu’offrent ces trois géants du Cloud. Pour avoir plus d’informations sur ce qu’est le MLOps et ses avantages vous pouvez vous référer à l’article suivant : https://www.davidson.fr/blog/le-mlops-au-secours-du-data-scientist
NB : cet article fait suite à un état de l’art réalisé en toute indépendance vis-à-vis des trois éditeurs.
La gestion des données
Datasets
Ce que l’on appelle “Dataset” est l’ensemble des données qui vont être utilisées pour la création d’un modèle de Machine Learning. Il s’agit à la fois des données utilisées pour l’entrainement ainsi que des données utilisées pour vérifier le bon fonctionnement du modèle.
Microsoft et Google proposent une couche d’abstraction qui permet de créer des Datasets à partir de ses données. Le principal avantage par rapport à utiliser directement les données stockées dans un fichier csv ou une base de données est de pouvoir versionner facilement les données d’entrainement.
Features store
En Machine Learning les “features” sont les informations qui décrivent les données. Par exemple si l’on souhaite prédire les prix d’appartements les features pourraient être : la localisation, la surface, le nombre de pièces, l’étage etc… On peut donc avoir à la fois des features numériques et des features textuelles. Les algorithmes ont besoin de données numériques sous un certain format pour s’entrainer. Il y a donc toute une phase de “features engineering” où le data scientist doit transformer les features initiales en features “consommables” par l’algorithme.
C’est ici qu’interviennent les features stores : ils permettent de stocker directement les features construites par le Data Scientist à partir des données initiales. Les avantages d’un features store sont les suivants :
- Mutualiser la création des features utilisables par les algorithmes, et ainsi alléger la charge de travail nécessaire à la phase de features engineering
- S’assurer que les features sont générées de la même manière entre la phase d’entrainement et la phase de prédiction lorsque le modèle est en production
Google et Amazon proposent ce service de features store directement intégré à leur solution. Microsoft lui le propose via son partenaire Databriks.
Analyse & Nettoyage des données
L’analyse et le nettoyage des données sont des étapes longues et fastidieuses par lesquelles le Data Scientist est obligé de passer. En général cette tâche est réalisée avec du code sur un Notebook.
Amazon propose une fonctionnalité intitulée “SageMaker Data Wrangler” qui permet de réaliser cette tâche sans code. Microsoft le propose aussi via “Azure Machine Learning Designer”. Les avantages sont :
- De donner la main au métier pour qu’ils puissent travailler eux-mêmes les données puisque c’est eux qui ont le plus de connaissances sur ces dernières
- De gagner en efficacité
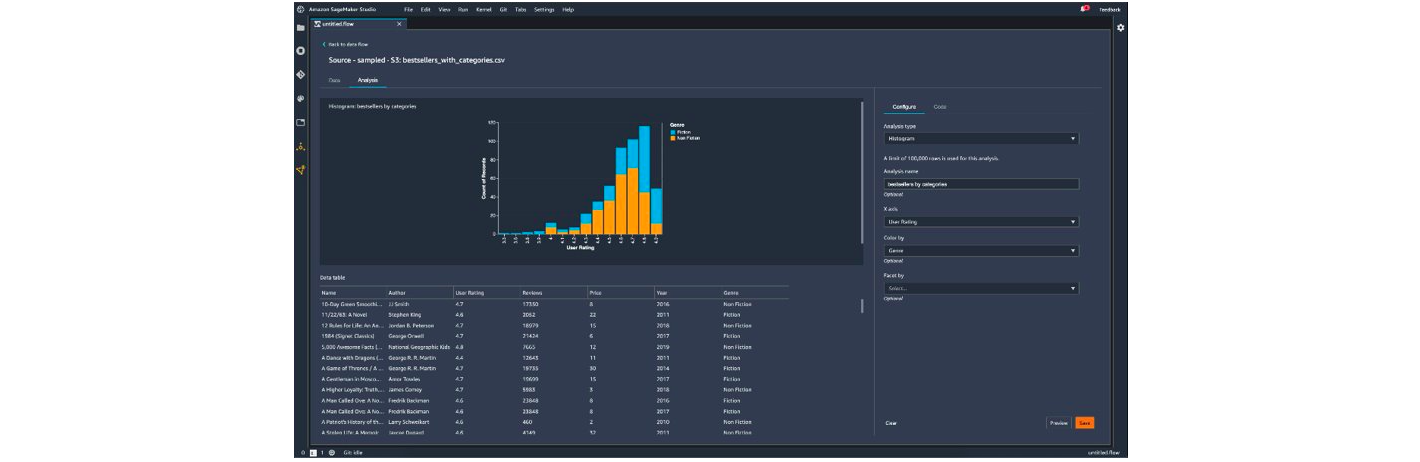
Ci-dessous des captures des studios Amazon et Microsoft permettant de faire du nettoyage de données sans code :
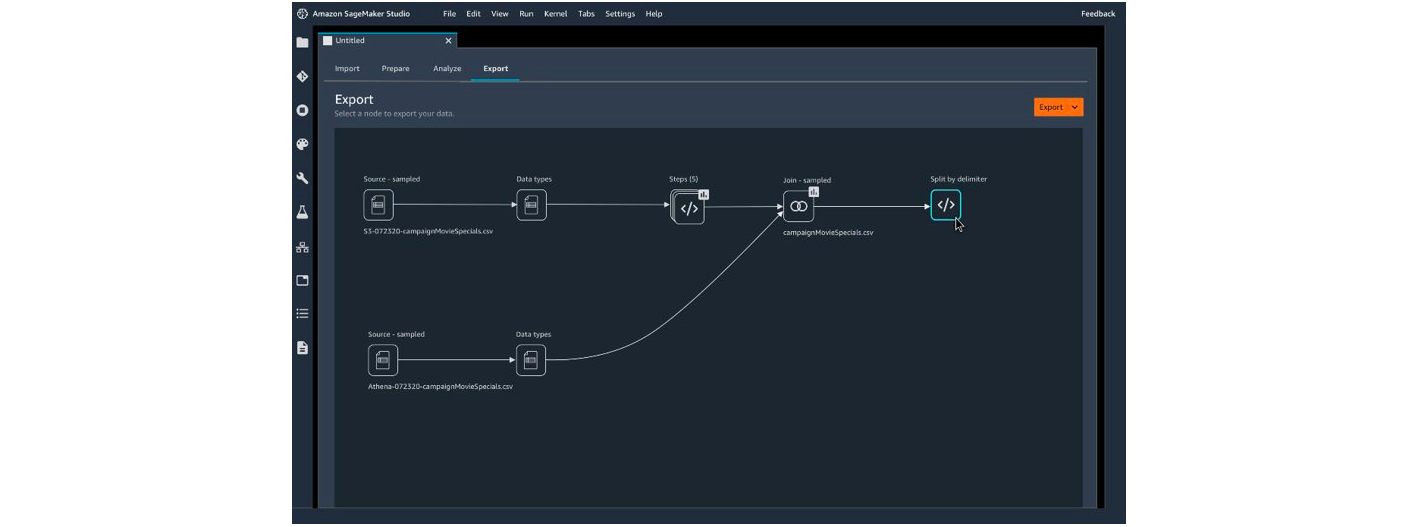
Pour la partie analyse Microsoft propose d’afficher des statistiques sur les données (valeur manquantes, minimum, maximum etc.…), Amazon propose en plus de créer des visualisations (histogrammes, nuage de points…).
Récapitulatif des 3 solutions sur La gestion des données

L’entrainement de modèles
Auto-ML
Les trois solutions cloud possèdent une fonctionnalité d’auto-ML, accessible depuis une interface graphique ou bien via du code.
L’auto-ML consiste à générer automatiquement un algorithme de Machine Learning. Il se charge de :
- Tester différents types de features engineering
- Tester différents algorithmes
- Sélectionner le meilleur des algorithmes
Une personne qui ne s’y connait pas en Machine Learning peut donc de façon autonome créer ses propres modèles : il lui suffit d’indiquer les données à utiliser, la colonne à utiliser comme label, et lancer l’entrainement.
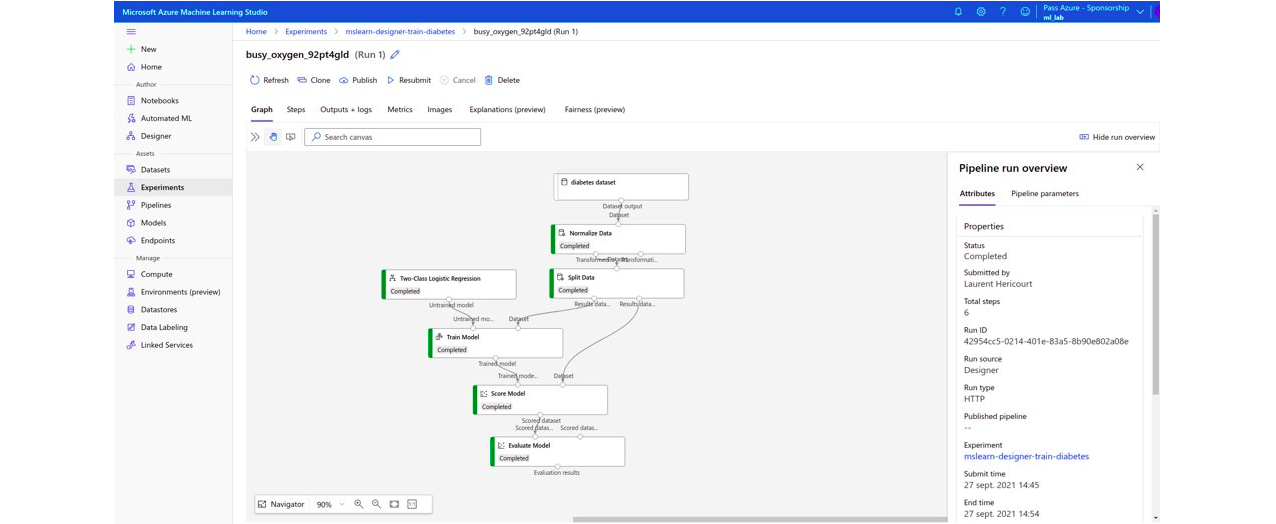
Microsoft Azure permet de consulter sous forme de graphes les modèles testés et les transformations sur les données réalisées automatiquement. A noter que pour des non-initiés ces graphes ne sont pas très parlants.
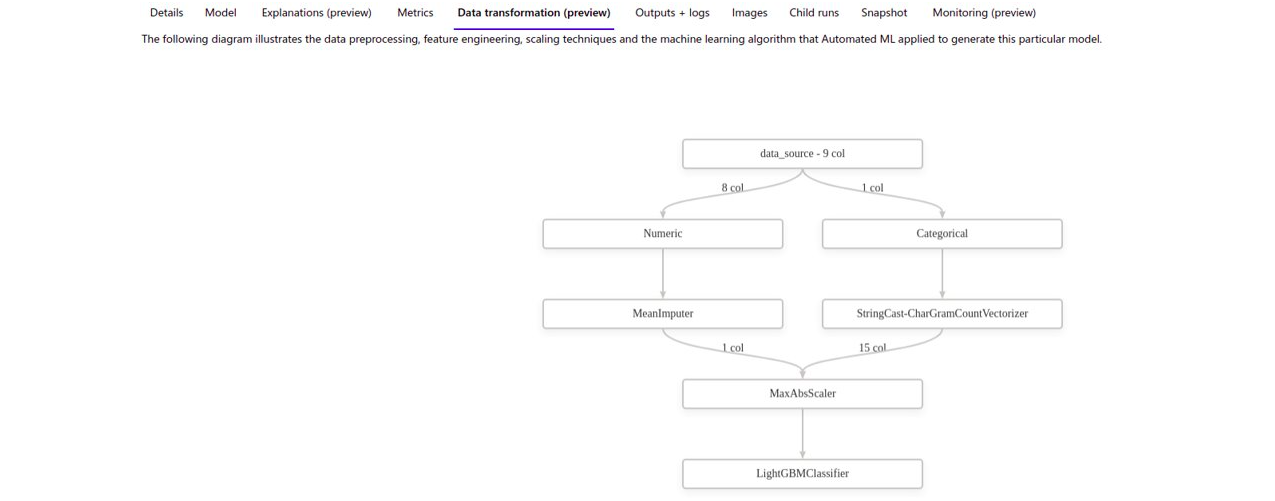
Amazon Vertex quant à lui ne propose pas d’explication si on utilise la solution purement graphique (solution intitulée SageMaker Canvas). Cependant si on utilise l’auto-ML via du code (solution intitulée SageMaker Autopilot) un Notebook est généré décrivant sous forme de texte les tests réalisés :

Pour Google les informations sur les modèles testés sont disponibles dans des logs sous format JSON, donc pas forcément simples à lire :
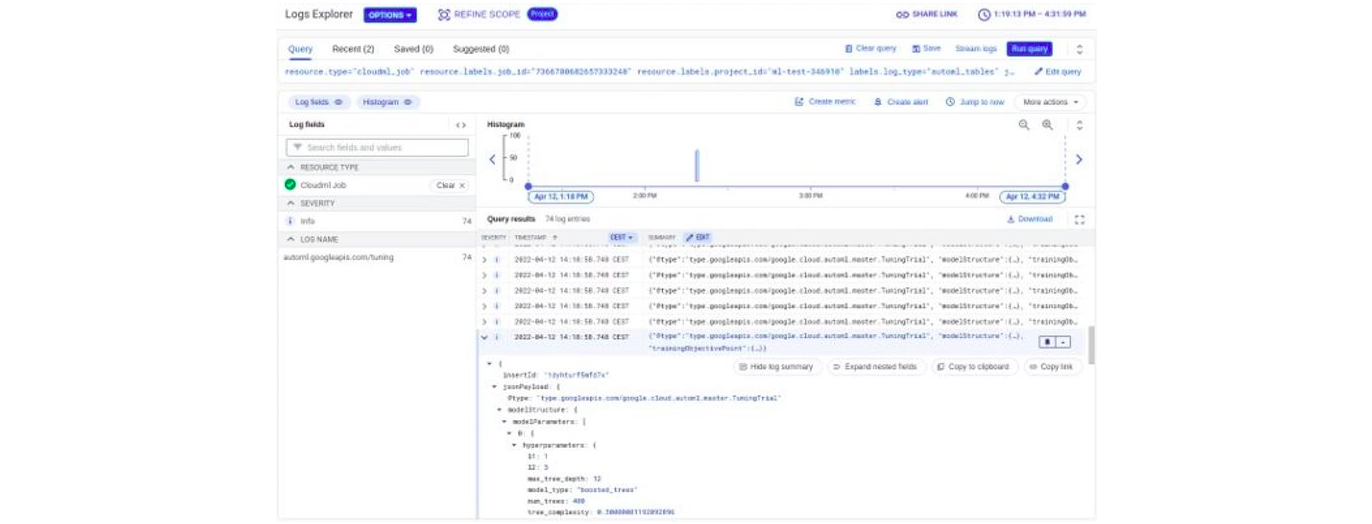
Le dernier point à noter est que la solution de Google semble être un peu légère sur la partie automatisation du features engineering par rapport à ses concurrentes.
Ci-dessous un tableau comparatif de notre ressenti sur ces 3 solutions d’AutoML :

En conclusion : la fonctionnalité d’AutoML peut sembler magique toutefois elle n’est pas sans risque. Mettre en production des modèles que l’on ne maitrise pas n’est pas conseillé. Comment le débugger si on ne sait pas comment il fonctionne ? Comment l’analyser ? En revanche cette fonctionnalité est très intéressante en tant que première étape pour un Data Scientist. Il pourra, en quelques clics ou lignes de code, obtenir un premier aperçu des modèles qui fonctionnent le mieux.
Entrainement de modèles “manuels”
On sous-entend par “manuel” le fait d’entrainer ses propres modèles sans passer par de l’autoML.
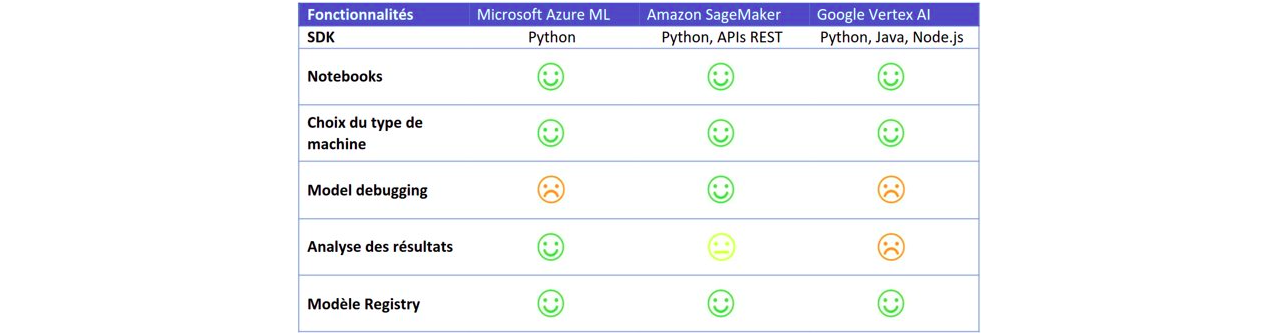
Les 3 solutions proposent à peu près la même chose à savoir :
- Une environnement Notebook pour faire des tests, de l’exploration de données, des petits entrainements, etc…
- Des librairies (Python, Node.js… ) pour interagir avec l’environnement Cloud (création de datasets, de modèles, d’endpoints…)
- La possibilité de choisir le type d’instance de machine sur laquelle exécuter l’entrainement. C’est dans ce dernier point que réside toute la puissance des solutions Cloud : en quelques clics ou quelques lignes de code il est possible d’exécuter un entrainement sur n’importe quel type de machine (choix du nombre de CPUs, de la mémoire, de nombre de GPUs)
- La possibilité de tester son code en local plutôt que directement sur le Cloud, afin de ne pas avoir à chaque fois à démarrer une instance Cloud pour faire le moindre test
- Un Modèle Registry pour stocker et versionner ses modèles
Microsoft sur cette partie d’“entrainements manuels” donne la possibilité de générer des modèles en passant par l’interface graphique du “Designer” et donc sans faire de code. Il est nécessaire d’avoir des compétences en Machine Learning pour utiliser cette fonctionnalité. De plus le Designer n’est pas des plus intuitifs : l’intérêt est donc limité.
En revanche le point fort de Microsoft se situe sur la partie comparaison de modèles ; l’interface graphique est très claire et très simple d’utilisation.
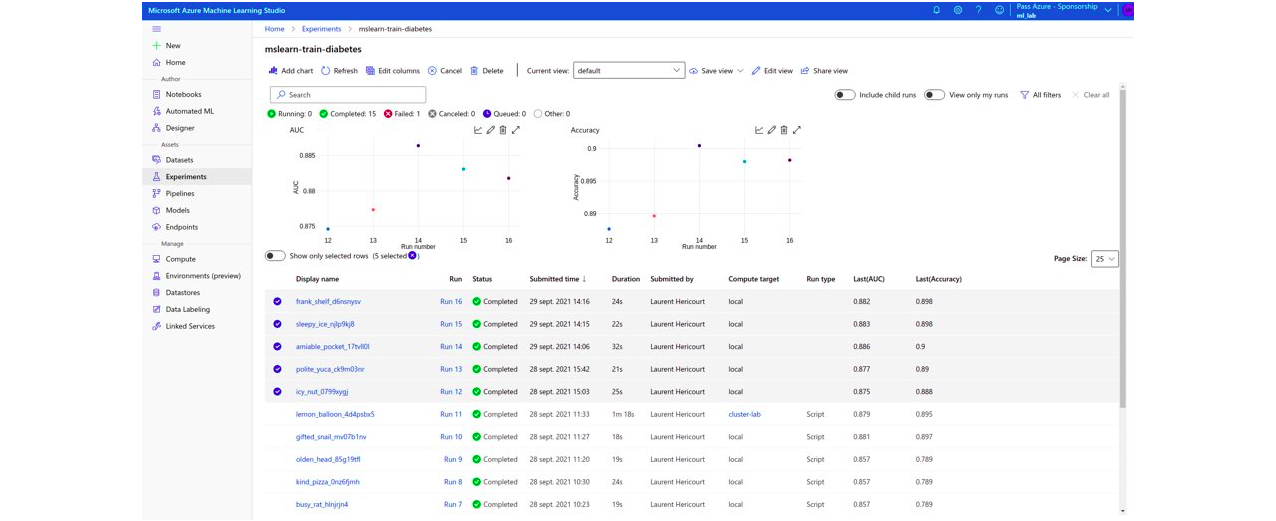
Avec la solution d’Amazon il est aussi possible de comparer les modèles, de façon moins intuitive néanmoins.
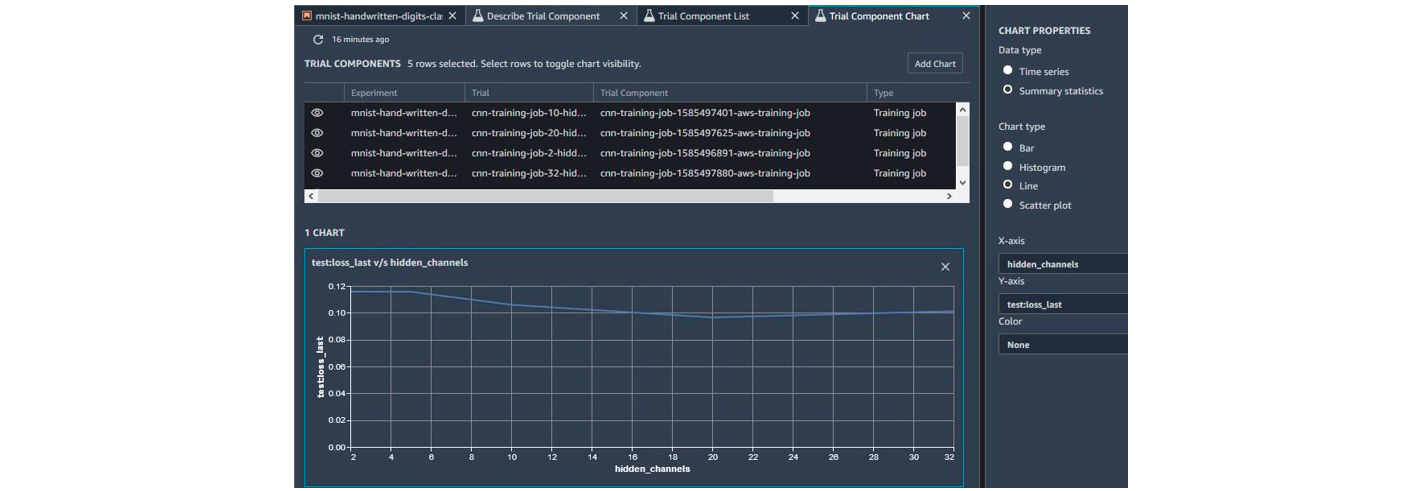
Amazon propose cependant tout une liste d’indicateurs et de règles permettant de faciliter le debugging d’un modèle.
Côté Google il est possible d’utiliser Tensorboard. Cependant il n’y a pas d’intérêt particulier à utiliser la version Cloud par rapport à la version que l’on peut installer en local.
Ci-dessous le récapitulatif des fonctionnalités d’entrainement des modèles.
L’Intelligence Artificielle éthique
L’IA éthique consiste à s’assurer que les modèles déployés soient respectueux, transparents et équitables. De façon plus détaillée il s’agit entre autres de :
- Ne pas reproduire les biais de la sociétaux (discrimination sur tel ou tel critère)
- Être capable de comprendre pourquoi l’algorithme a pris telle ou telle décision
- Respecter la vie privée des individus
- Respecter la liberté des individus
- Respecter l’environnement
Sur la partie explicabilité des modèles les trois éditeurs proposent l’utilisation des “SHAP values”. Microsoft propose en plus LIME et PFI, Google ajoute XRAI et Integrated Gradient.
Microsoft propose une très bonne interface graphique permettant de comparer le comportement du modèle en fonction de différents types de population.
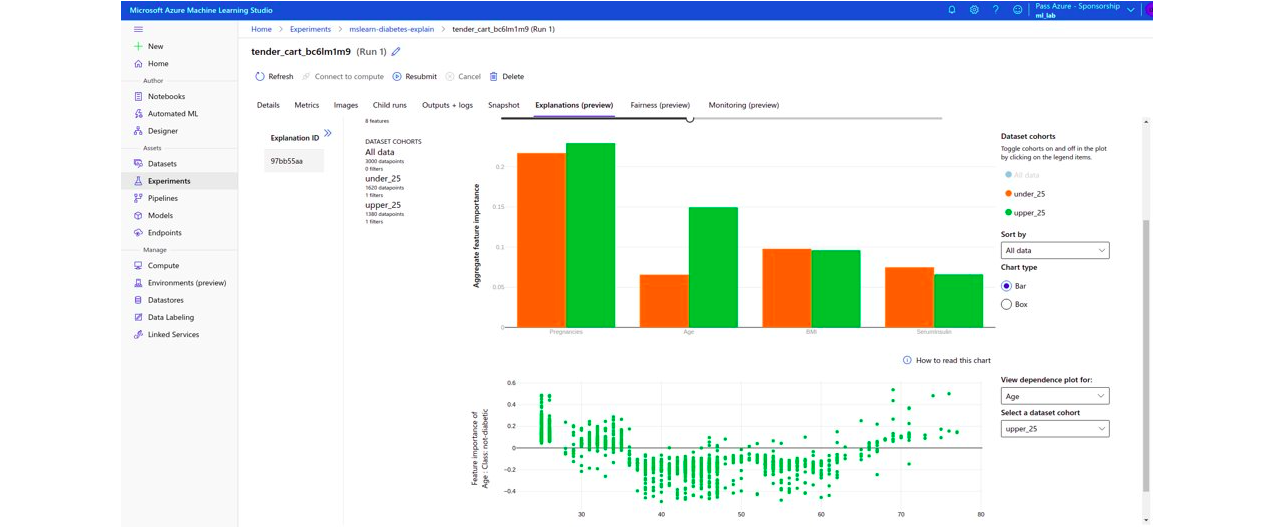
Amazon propose lui une interface sommaire . Google n’en propose pas.
Sur la partie “impartialité des modèles” Azure propose quelques indicateurs (il utilise le package fairlearn), Amazon en propose une vingtaine, avec une explication détaillée de chacun, et Google aucun.
Ci-dessous le récapitulatif des fonctionnalités d’IA éthique.

Le déploiement de modèles
Une fois le modèle entrainé les solutions proposent de le déployer en quelques clics ou via quelques lignes de code. Déployer un modèle signifie mettre à disposition un “endpoint” (une API REST) qui prend en entrée la donnée sur laquelle faire la prédiction, et qui retourne la prédiction du modèle.
Il est possible dans le déploiement de rajouter des traitements en amont ou en aval de la prédiction via du code spécifique.
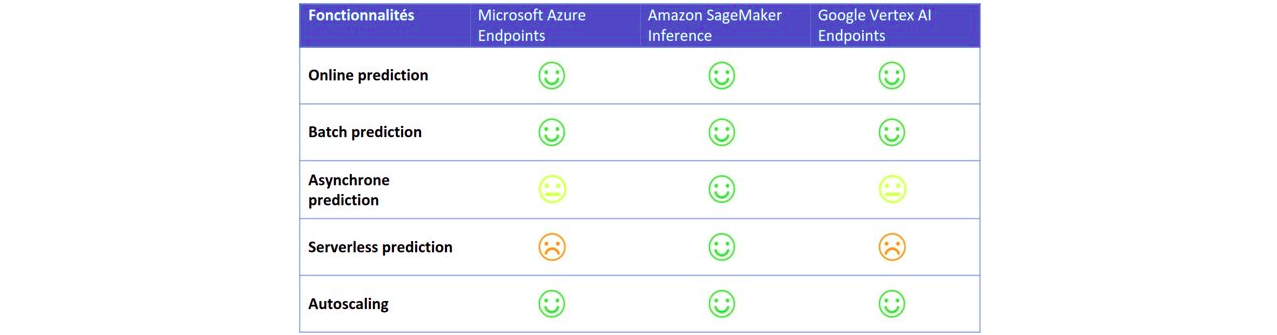
Les trois cloud provider proposent des prédictions dites :
- “Online” : il s’agit de prédictions faites en temps réel (requêtes synchrones) ; il est possible de faire des prédictions sur une unique donnée ou sur plusieurs
- “Batch” : il s’agit de prédictions qui sont faites de manière asynchrone, les résultats sont ensuite sauvegardés, mais pas renvoyés directement à l’utilisateur ; ceci est généralement utilisé lorsqu’il faut faire des prédictions sur des gros volumes de données
Amazon SageMaker propose deux autres types de déploiement :
- “Prédictions asynchrones” : ce type de prédictions peut être utilisé lorsque l’on souhaite faire des prédictions presque en temps réel, mais où l’on ne souhaite pas bloquer l’utilisateur le temps de la prédiction. Par rapport à la prédiction de type “batch” l’utilisateur (ou client) peut être automatiquement notifié et on peut donc récupérer automatiquement le résultat.
- “Prédictions serverless” : ce type de déploiement permet de se décharger complètement de la partie dimensionnement de l’infrastructure et de la politique de mise à l’échelle. Le dimensionnement de l’infrastructure se fait de façon automatique en fonction de la charge à l’instant t. Le point important pour pouvoir utiliser ce type de déploiement est que le service doit tolérer les démarrages à froid, car le service n’est pas disponible le temps que la première instance se mette en route.
Le monitoring des modèles en production
Les trois solutions permettent de stocker les prédictions faites par les modèles et les données qui ont conduit à ces prédictions.
Microsoft utilise la solution Azure Application Insights pour stocker ces informations dans des logs. Il est possible de faire des requêtes dans ces logs en utilisant le langage Kusto (KQL). Cependant ces logs ne sont pas facilement exploitables, ci-dessous un exemple de ce que l’on peut avoir :

Chez Google les prédictions sont stockées dans leur Data Warehouse BigQuery. Si l’on n’est pas un expert en requêtes BigQuery les résultats ne sont pas facilement exploitables non plus.
Finalement Amazon sauvegarde les prédictions dans des fichiers sur S3.
Les 3 solutions offrent aussi une fonctionnalité d’analyse de “drift”. Ce que l’on appelle “drift” est le changement de distribution des données au cours du temps. Il est important de garder un œil dessus car si les données évoluent le modèle ne sera plus performant. Il sera donc nécessaire de le ré-entrainer.
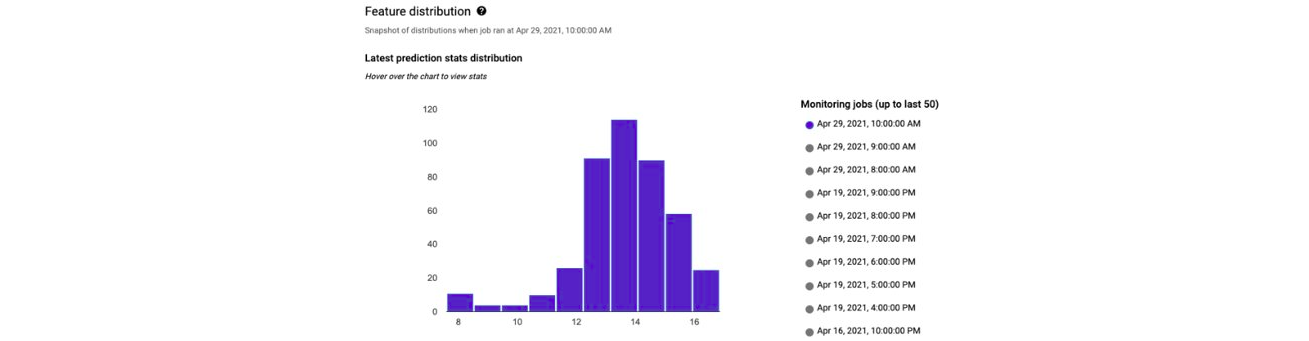
Il est aussi possible d’envoyer automatiquement des alertes en cas de changement important des distributions c’est-à-dire de drift.
Un point d’attention : dans certains cas le calcul des indicateurs de Drift ne sont pas expliqués, il est donc difficile de définir un seuil pour automatiser les alertes.

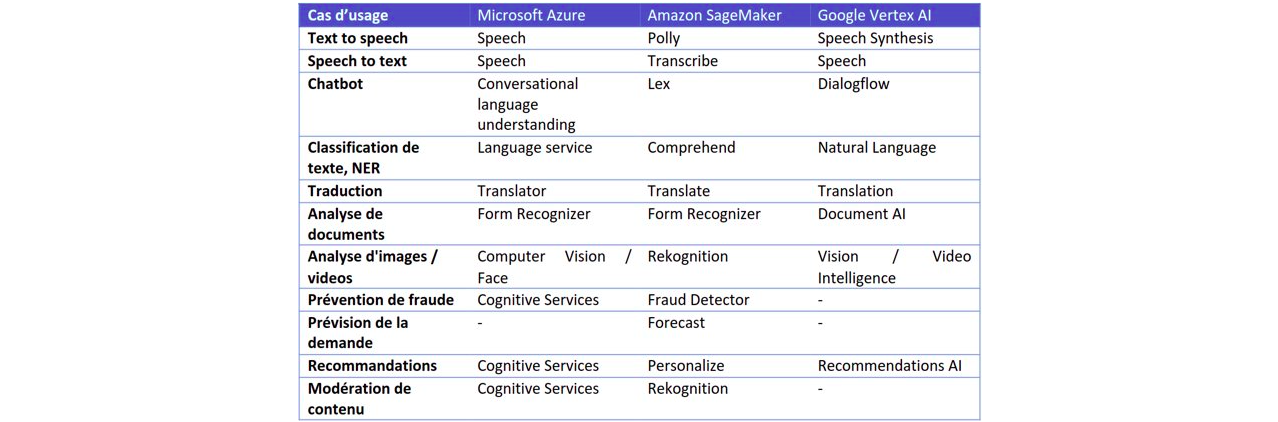
Les services d’IA spécifiques
Les trois Cloud Providers fournissent des solutions d’Intelligence Artificielle pour des cas d’utilisation bien précis. Ce sont des cas d’utilisation qui sont souvent complexes à développer soi-même (classification d’images, chatbot…).
Il suffit de fournir ses propres données labellisées au service, un algorithme est ensuite entrainé automatiquement dessus puis, si les résultats sont convaincants, il peut être déployé.
Le tableau ci-dessous liste les différents cas d’usage traités par chaque éditeur en précisant le nom de la solution.
Quelques informations sur les tarifs
Les tarifs se décomposent sur plusieurs postes : les instances sur lesquels les studios / Notebooks tournent, les instances sur lesquelles les modèles sont entrainés, les instances sur lesquelles les modèles sont déployés, le stockage, le réseau, les load balancer etc…
Il est donc très compliqué d’estimer le coût d’utilisation de ces solutions pour ses propres besoins. Dans le tableau ci-dessous nous comparons le prix des instances de calculs qui sont les postes principaux de coûts, les prix sont pour la région Est des Etats-Unis :

Synthèse et conclusion
Les 3 cloud providers offrent des services à peu près similaires. Le point fort d’Azure est son studio simple d’utilisation, celui d’Amazon réside en ses options variées de déploiement. De notre point de vue Google ne dispose d’aucun différentiateur fort.
Ces outils apportent une vraie plus-value pour les Data Scientists grâce :
- A l’auto-ML qui permet au Data Scientist d’avoir rapidement une première estimation des performances que l’algorithme pourra atteindre
- Au studio qui permet d’afficher l’historique des expériences réalisées et ainsi de garder une trace des travaux effectués
- Aux fonctionnalités de déploiement qui permettent de donner la main au Data Scientist pour déployer lui-même ses modèles
A noter : Les différentiateurs n’étant pas nombreux, nous recommandons que e le choix d’une solution se fasse en fonction de l’écosystème dont chacun dispose à l’instant t, le recours au Machine Learning ne justifiant pas seul du changement de cloud provider.
Laurent HERICOURT – Lead Data Scientist